# 3. 树、二叉树、二叉搜索树的实现和特性
# 定义
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
# 结构
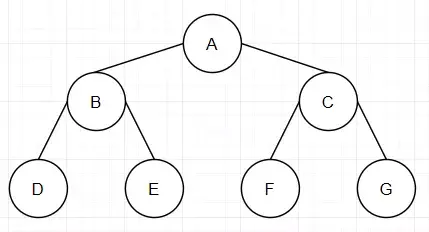
# 与树相关的术语
树的结点(node):包含一个数据元素及若干指向子树的分支;
孩子结点(child node):结点的子树的根称为该结点的孩子;
双亲结点:B 结点是A 结点的孩子,则A结点是B 结点的双亲;
兄弟结点:同一双亲的孩子结点;堂兄结点:同一层上结点;
祖先结点: 从根到该结点的所经分支上的所有结点
子孙结点:以某结点为根的子树中任一结点都称为该结点的子孙
结点层:根结点的层定义为1;根的孩子为第二层结点,依此类推;
树的深度:树中最大的结点层
结点的度:结点子树的个数
树的度:树中最大的结点度。
叶子结点:也叫终端结点,是度为 0 的结点;
分枝结点:度不为0的结点;
有序树:子树有序的树,比如家族树;
无序树:不考虑子树的顺序;
# 二叉树遍历
前序: 根-左-右
中序: 左-根-右
后序: 左-右-根
递归
数的操作一般使用递归, 而不是用循环
# 二叉搜索树
二叉搜索树, 也称二叉排序树, 有序二叉树, 排序二叉树, 是指一颗空树或者具有下列性质的二叉树
- 左子树上所有节点的值均小于它的根节点的值
- 右子树上所有节点的值均大于它的根节点的值
- 以此类推: 左,右子树也分别为二叉查找树(这就是重复性!)
时间复杂度
普通二叉树的查询和插入都是O(n)的
二叉搜索树的查询, 插入或删除都是O(logN)的, 说明二叉搜索树较普通二叉树提速了
# 堆 Heap
Heap: 可以迅速找到一堆数中的最大或者最小值的数据结构
将根节点最大的堆叫做大顶堆或者大根堆, 根节点最小的堆叫做小顶堆或小根堆 常见的堆有二叉堆 斐波那契堆等
假设是大顶堆, 则常见操作(API):
find-max: O(1) delete-max: O(logN) insert(create): O(logN) or O(1)
# 二叉堆性质
通过完全二叉树来实现(注意: 不是二叉搜索树);
完全二叉树
定义:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1 ~ 2h 个节点。
二叉堆(大顶)它满足下列性质:
- [性质1] 是一颗完全树
- [性质2] 数中任意节点的值总是 >= 其子节点的值
将数组转化成二叉堆
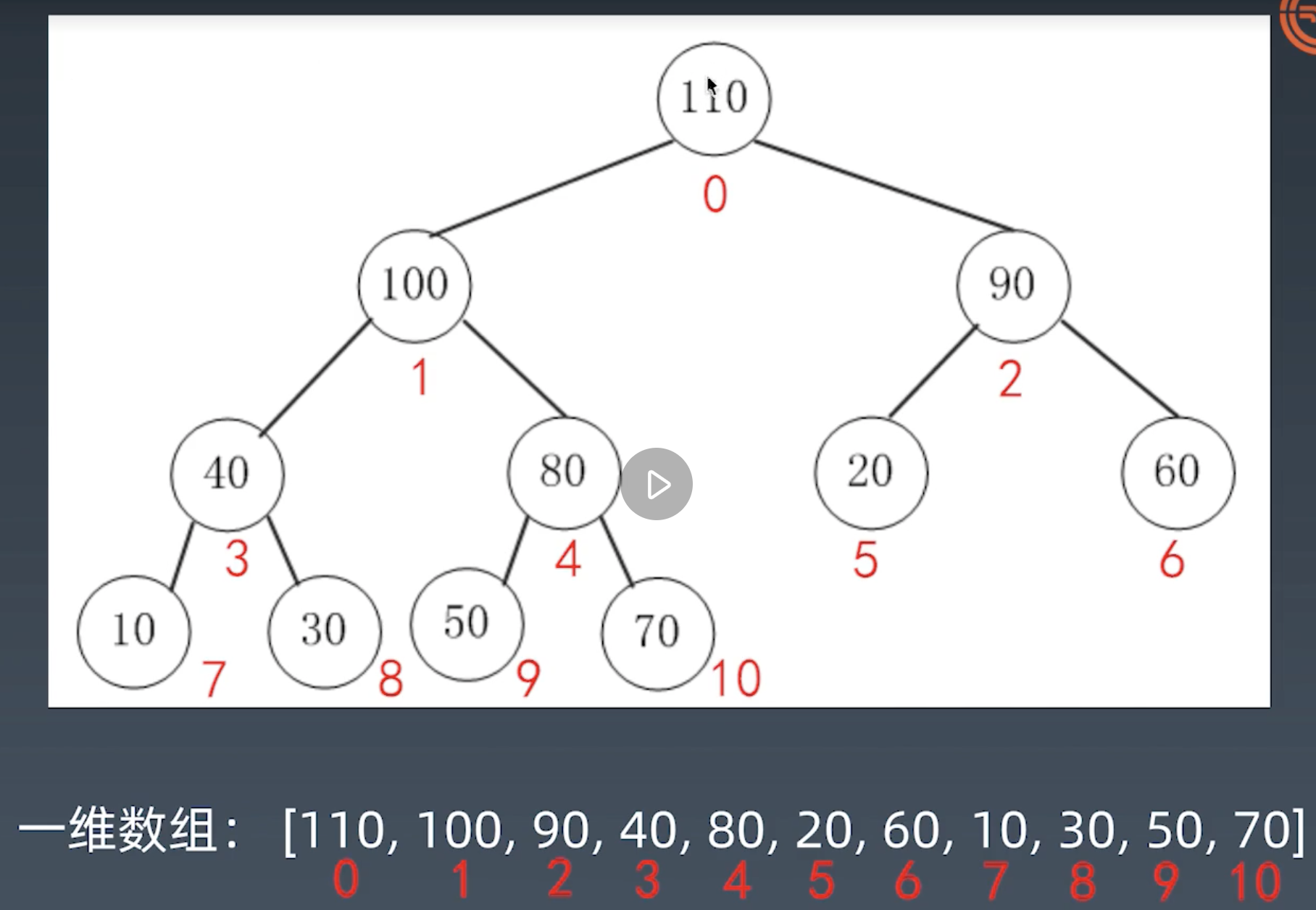
- 根节点(顶堆元素)是: a[0]
- 索引为i的左孩子的索引是 (2 * i + 1)
- 索引为i的父节点的索引是 floor((i - 1) / 2)
# 二叉堆的主要操作
- insert: 插入节点
- delete: 删除节点
- max-hepify: 调整分支节点堆性质
- rebuildHeap: 重新构建整个二叉堆
- sort: 排序
# 插入操作步骤:
- 新元素一律先插入到堆的尾部
- 依次向上调整整个堆的结构(一直到根即可)
- 时间复杂度: O(log2N)
举例:

# 删除堆顶操作
- 将堆尾元素替换到顶部(即对顶被替代删除掉)
- 依次从根部向下调整整个堆的结构(一直到堆尾即可)

实现
二叉堆是堆(优先队列 priority_queue)的一种常见且简单的实现; 但是并不是最优的实现